TLDR: First open-source implementation of Soft Policy Optimization, an off-policy RL algorithm that works with LMs. This makes many RL experiments faster and cheaper.
Background - Post-training
In 2024, OpenAI released o1 and showed that you can post-train an LLM to generate a chain-of-thought which improves accuracy. A few months later, Deepseek published their R1 model which used Group Relative Policy Optimization (GRPO).
Before GRPO, most people used Proximal Policy Optimization (PPO). Here’s how PPO works in this context:
- Copy the base model. Call this policy π.
- Generate outputs. Prompt π on a batch of tasks and measure its performance (for example, the fraction of math problems it solves correctly). That measurement is the reward (a number between 0 and 1).
- Avoid naive back-prop. You cannot simply back-propagate that reward because there is no correct sequence of tokens to compare against. If you rewarded each token in proportion to the overall score, you would end up pushing the model in random directions (high variance) and degrade its general language ability.
- Introduce a value baseline. You add a small value head on top of π that predicts the expected reward for each prompt. After collecting actual rewards you compare them to the baseline: if π did better than expected, you boost the probabilities of the tokens it chose; if it did worse, you suppress those probabilities. This keeps parameter updates focused on the real errors.
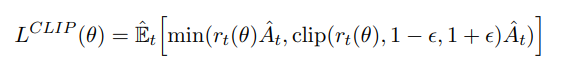
Group Relative Policy Optimization (GRPO)
GRPO does exactly the same reward-vs-baseline trick as PPO, but it removes the extra value network. Instead, you run π multiple times on the same prompt, compute the average reward across that group of samples, and use that average as your baseline. You still nudge π up or down token by token based on whether each sample beat or fell short of the group mean, but you save memory by never storing a separate value model.
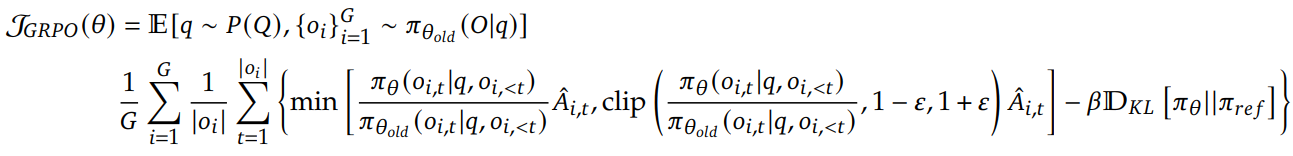
Soft Policy Optimization (SPO)
SPO drops any reward baseline and replaces it with a KL-based drift penalty.
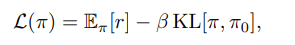
Because it never subtracts a value or group mean, SPO is fully off-policy. You can train off samples generated by a non-policy model.
Our Approach
We have released a basic code implementation of SPO.
This basic implementation trains Qwen-2.5-1.5B-Instruct to pick smaller numbers when randomly generating numbers between 1 and 100.
root@c20fc8f683fd:/workspace# python -m spo.dummy_experiment
--- Starting SPO Dummy Experiment ---
Device: cuda
Local Model: Qwen/Qwen2.5-1.5B-Instruct
Off-policy Sampler: 100% off-policy (uniform 1-100)
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
SPOModel initialized:
- Policy model (pi_theta): Qwen/Qwen2.5-1.5B-Instruct
- Reference model (pi_ref): Qwen/Qwen2.5-1.5B-Instruct (frozen)
- Device: cuda
--- Sampling from untrained model pre-training ---
Initial Sample 1: 74
Initial Sample 2: 74
Initial Sample 3: 74
Initial Sample 4: 74
Initial Sample 5: 74
Initial Sample 6: 74
Initial Sample 7: 74
Initial Sample 8: 74
Initial Sample 9: 74
Initial Sample 10: 74
Estimating Q0 using pi_ref with 256 samples...
Q0 estimation: 256 valid samples, 0.0% success rate
WARNING: Very low success rate (0.0%). Using fallback Q0 estimate.
--- Initial Q0 estimate (from pi_ref): -0.5000 ---
--- Epoch 1/3 ---
Generating 200 off-policy samples...
Generating 200 uniform off-policy samples (1-100)...
--- First 5 training samples ---
Sample 1 (off-policy): (Reward: -0.606)
Completion: "61"
Sample 2 (off-policy): (Reward: -0.919)
Completion: "92"
Sample 3 (off-policy): (Reward: -0.384)
Completion: "39"
Sample 4 (off-policy): (Reward: -0.020)
Completion: "3"
Sample 5 (off-policy): (Reward: -0.475)
Completion: "48"
-------------------------------------------
Using pre-computed Q0 estimate for this epoch: -0.5000
Training on generated samples...
Training on samples: 0%| | 0/200 [00:00<?, ?it/s]DEBUG - Q0: -0.5000, Cumulative Advantage: 0.0000, Q_terminal: -0.5000, Reward: -0.6055
Training on samples: 50%|██████████████████████████████████████████████████████████████ | 100/200 [00:12<00:12, 7.91it/s, guess=12, reward=-0.111, loss=0.2178]DEBUG - Q0: -0.5000, Cumulative Advantage: -0.3711, Q_terminal: -0.8711, Reward: -0.7578
Training on samples: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:25<00:00, 7.86it/s, guess=74, reward=-0.737, loss=0.0055]
Epoch 1 Summary: Avg Loss: 0.0739 | Avg Reward: -0.496
Current model predictions: [25, 23222525, 521, 235, 5221] (avg: 4645705.4, target: 1)
✓ New best distance to target: 4645704.4
--- Epoch 2/3 ---
Re-estimating Q0 for stability...
Estimating Q0 using pi_theta with 256 samples...
Q0 estimation: 256 valid samples, 7.4% success rate
Q0 estimate: -0.5000 → -0.1836 (change: +0.3164)
Generating 200 off-policy samples...
Generating 200 uniform off-policy samples (1-100)...
Using pre-computed Q0 estimate for this epoch: -0.1836
Training on generated samples...
Training on samples: 0%| | 0/200 [00:00<?, ?it/s]DEBUG - Q0: -0.1836, Cumulative Advantage: 0.0610, Q_terminal: -0.1226, Reward: -0.0403
Training on samples: 50%|██████████████████████████████████████████████████████████████ | 100/200 [00:11<00:11, 8.45it/s, guess=12, reward=-0.111, loss=0.0067]DEBUG - Q0: -0.1836, Cumulative Advantage: -0.6680, Q_terminal: -0.8516, Reward: -0.9297
Training on samples: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:23<00:00, 8.44it/s, guess=12, reward=-0.111, loss=0.0019]
Epoch 2 Summary: Avg Loss: 0.0183 | Avg Reward: -0.487
Current model predictions: [2, 2, 2, 2, 2] (avg: 2.0, target: 1)
✓ New best distance to target: 1.0
--- Epoch 3/3 ---
Re-estimating Q0 for stability...
Estimating Q0 using pi_theta with 256 samples...
Q0 estimation: 256 valid samples, 100.0% success rate
Q0 estimate: -0.1836 → -0.0064 (change: +0.1772)
Generating 200 off-policy samples...
Generating 200 uniform off-policy samples (1-100)...
Using pre-computed Q0 estimate for this epoch: -0.0064
Training on generated samples...
Training on samples: 0%| | 0/200 [00:00<?, ?it/s]DEBUG - Q0: -0.0064, Cumulative Advantage: 0.0001, Q_terminal: -0.0063, Reward: -0.1211
Training on samples: 50%|██████████████████████████████████████████████████████████████▌ | 100/200 [00:12<00:12, 7.70it/s, guess=3, reward=-0.020, loss=0.0038]DEBUG - Q0: -0.0064, Cumulative Advantage: -0.6992, Q_terminal: -0.7070, Reward: -0.7695
Training on samples: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:25<00:00, 7.91it/s, guess=39, reward=-0.384, loss=0.0018]
Epoch 3 Summary: Avg Loss: 0.0039 | Avg Reward: -0.473
Current model predictions: [2, 1, 2, 2, 2] (avg: 1.8, target: 1)
✓ New best distance to target: 0.8
--- Training finished ---
--- Sampling from trained model post-training ---
Generated 10 samples:
Sample 1: 2
Sample 2: 2
Sample 3: 1
Sample 4: 2
Sample 5: 2
Sample 6: 2
Sample 7: 2
Sample 8: 2
Sample 9: 2
Sample 10: 1
--- Dummy Experiment Finished ---In this simple demo, we used random numbers. But if you are a compute-bottlenecked researcher conducting RL experiments, you can use OpenRouter to quickly collect a massive number of off-policy trajectories to use with SPO. This is often preferable to wasting H100 hours and your own time on thousands of on-policy samples.
We hope this minimalist demo is helpful to the research community.
Ibrahim Ahmed